

Hooray, it’s Day 1 of Codebuff Launch Week! Watch our launch video above or check out the long form below, which has even more detail.
Also, check out our launch tweet — likes and retweets appreciated 🙏.
After a year of building agents, we’ve hit upon a multi-agent abstraction that allowed us to top Claude Code in our evals.
So today, we’re open sourcing and releasing our framework so anyone can build on top of it.
If you’re building a product with AI agents, this is for you!
If you’re a developer looking for the best coding agent, this is also for you. Try tinkering with our custom agents to improve your day-to-day development!
In this example, we see an orchestrator agent spawning a scout (”Lewis & Clark”), which in turn spawns a file explorer (”Dora the File Explorer”). The orchestrator continues on to spawn a planner (”Peter Plan”).
We built this framework to solve our own problem.
After a year developing a coding agent, our codebase had grown unwieldy with many scattered LLM calls and tools that were defined in pieces, with if statements sprinkled throughout the core agent loop implementing special cases.
We refactored our sprawling spaghetti code and iterated on a framework that could replicate all the capabilities of Codebuff. We ended up with something shockingly simple and powerful (never has a refactor gone so well!). Codebuff has been condensed into half-a-dozen agents, each defined by a simple Typescript file.
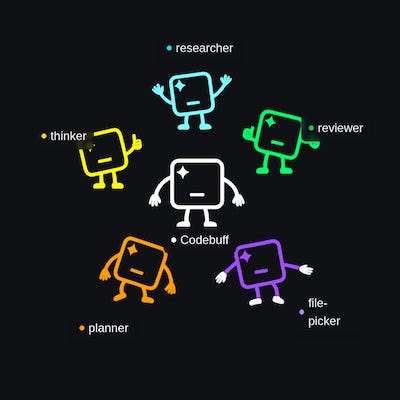
Delete your spaghetti code. Use our agent framework!
We are launching the open source Codebuff Agent SDK, so you too can delete your spaghetti code and make agents that compete with the best!
We already have Vly.ai (YC F24) building on top of our framework to make a Lovable competitor. Victor says it makes their agent “way smarter [and] better”. Danny Hsu (YC F24) building Aspects Studio says that “Codebuff’s agent SDK captured exactly how my agentic flows were set up and provides tooling for all of the hard parts.”
Agents as the composable unit
The core idea in our framework is that the agent is the composable unit, not individual LLM calls. An agent is simply a model with prompts and tools that is allowed to take multiple steps.
Each agent has a list of which other agents it is allowed to spawn. When run, an agent can dynamically spawn these subagents whenever it likes in order to accomplish a given task, frequently in parallel!
More on the framework below — but we’ve found it to be a highly configurable agent runner that solves the tricky parts of running agents. It's like the Claude Code SDK, but with more power: you can choose your model, customize prompts, and seamlessly mix in programmatic code to steer your agent.
Let’s see some examples that demonstrate what makes our framework easy to use and powerful.
Example 1: File Explorer
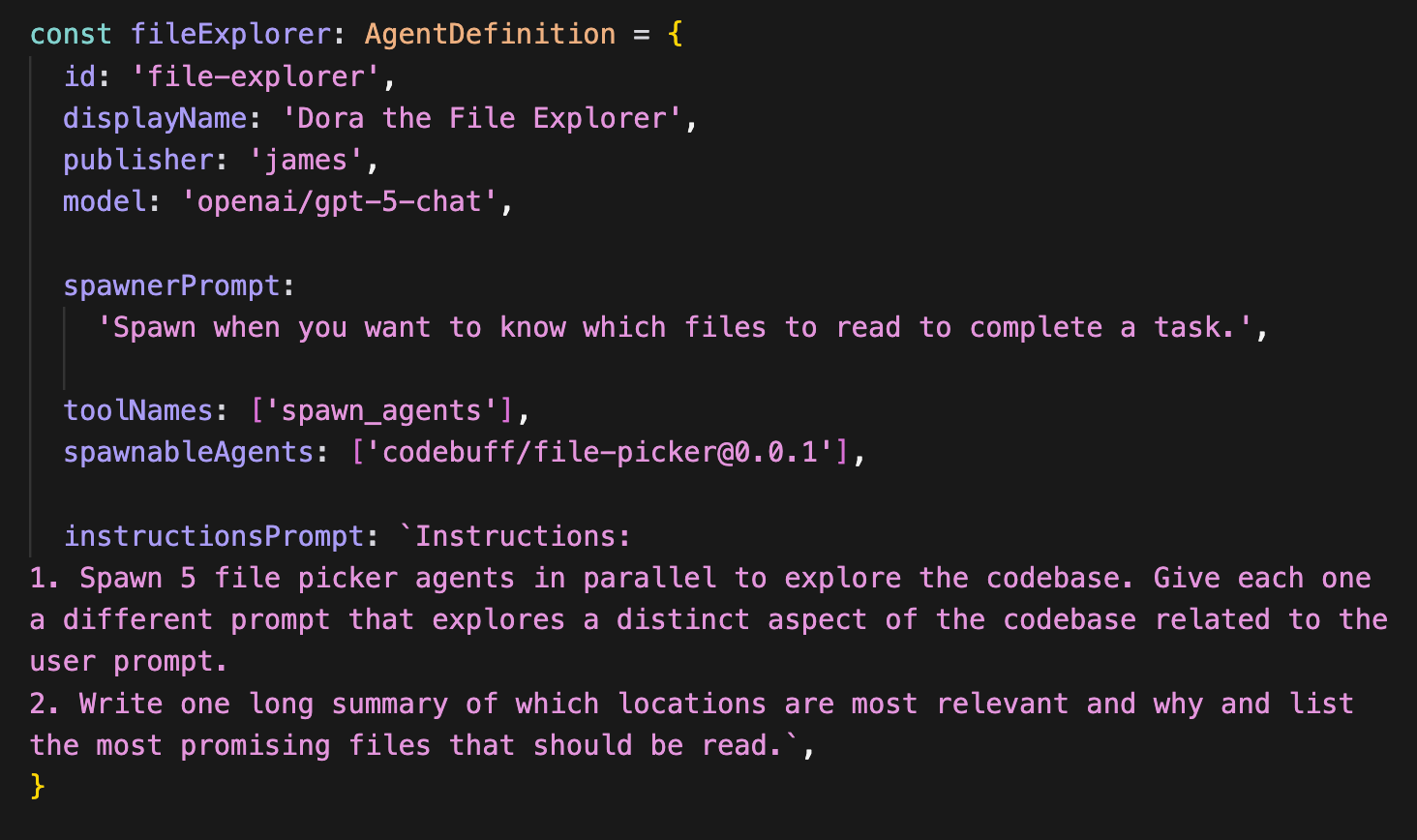
Ahh… that feeling when you deleted all your spaghetti code and your agents are simple again.
This file explorer agent is simply defined. The heart of it is the “instructionsPrompt” which can describe multiple steps for the agent to carry out.
Instead of always relying on the system prompt, our framework gets much higher rates of success by injecting instructions as a “user” role message at the bottom of the message history.
Example 2: Git Committer
To get even more control, you can mix in code! Our framework uniquely allows you to intersperse LLM generation with programmatic code using JavaScript generators (the syntax might look foreign, but it's surprisingly simple!).
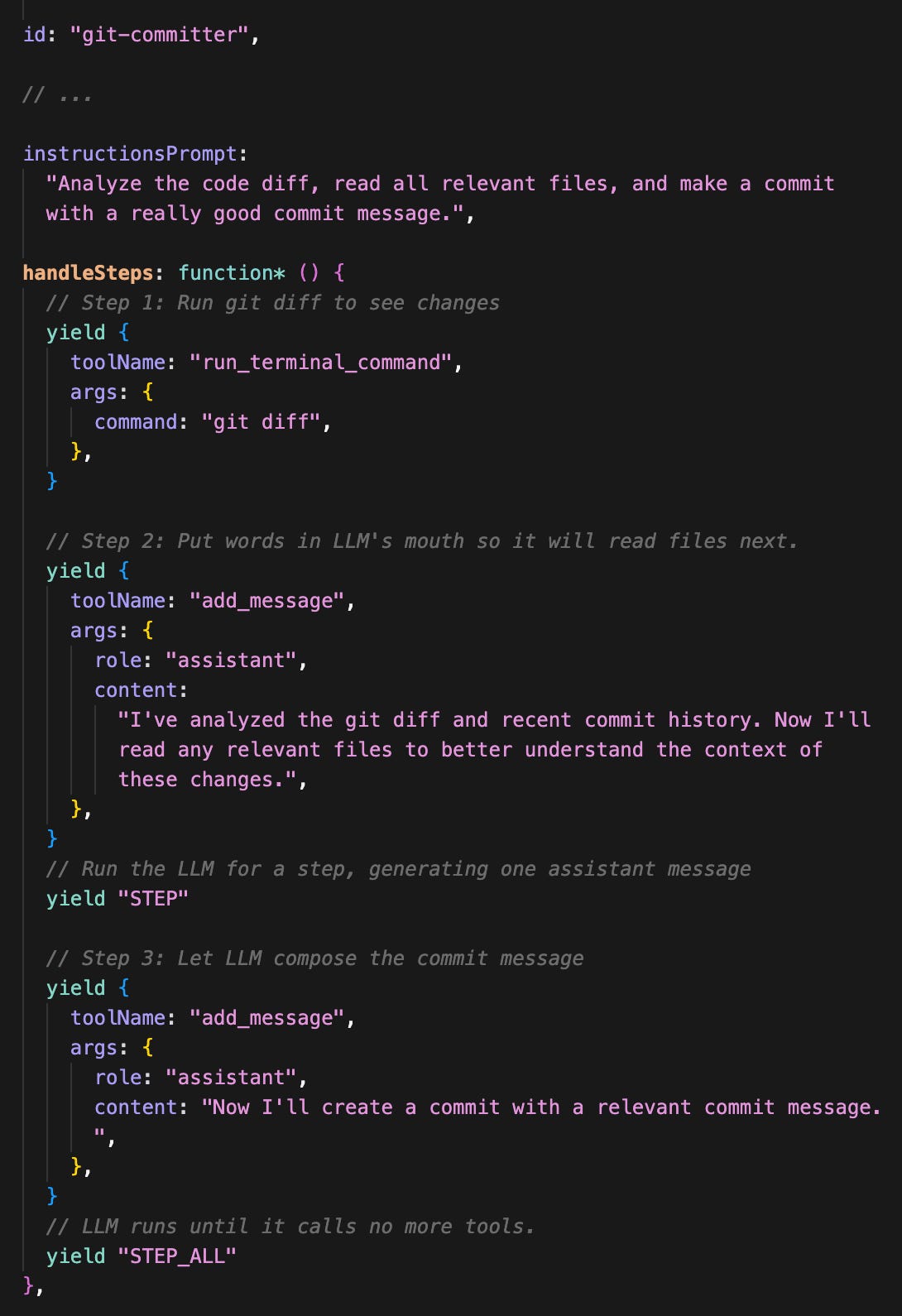
The handleSteps generator yields tool calls or instructions to “step” the LLM. It’s a superpower for agent workflows!
In this example, we always run git diff first, and then yield ‘STEP’ to run one LLM call that reads files chosen by the agent. Finally we use ‘STEP_ALL’ to let the agent take as many steps as it wants to generate the commit.
Compare this code to the equivalent code in another framework or by rolling your own. It’s literally 10x less code. Moreover, everything that defines the agent can be co-located in one file.
Example 3: The Orchestrator Pattern
One of the most exciting results from iterating with our framework is we came up with what we think is the next breakthrough architecture for coding agents — or even agents generally!
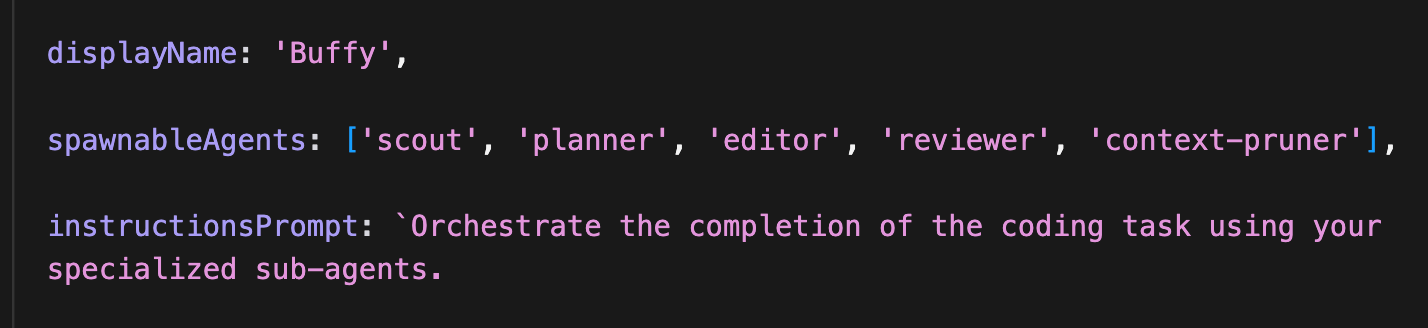
Actual code from our production coding agent!
We use an orchestrator agent with no tools at all, except for one tool to spawn agents. Everything that it does must be done by delegating to subagents.
The agents that it spawns are all crafted for specific purposes and use different models. Each agent defines a prompt used to inform the orchestrator of when it should be spawned.
And then… the orchestrator makes all the decisions of when to spawn which agent to accomplish the given task.
The magical part is that with this setup, we get for free near-perfect context management.
That’s because spawned agents don’t add their message history to the orchestrator’s, cluttering it up with tool results. Instead, they contribute just their final output, which can be whatever they think is important.
(Unlike Claude Code’s subagents, we have several options for defining an agent’s output, via the last assistant message, a structured output schema, or even a programmatic handler!).
This means that the orchestrator agent’s context window grows very slowly and includes all the essential information about what the user asked and what actions have been taken thus far!
I’m very excited to see what agents our community creates that can plug right into the orchestrator. Modular agents are the new MCP!
Get the SDK
Using our npm package, you can define agents, use any model on OpenRouter, and run them programmatically. You can even define your own custom tools, and (more on this soon!) publish agents and spawn other people’s agents!
All you need is a Codebuff API Key to get started (click here to get one in 10 seconds). Then simply call run() on the SDK client:
Get the Codebuff Agents SDK here. Learn more about our agent framework here.
Framework results
As a result of our migration to this framework, we have improved our code quality leaps and bounds, sped up our dev cycle time, made our code more reliable and testable, and increased our eval scores.
On our internal benchmark of 175+ distinct implementation tasks across open source codebases, we now achieve a 61% score compared to Claude Code's 53%.

In our BuffBench eval, we have a prompting agent pretend to be the user with the goal of implementing a hidden spec. Each spec is derived from a real git commit, and a judge agent compares the coding agent’s result with the real git diff to judge correctness, code quality, and task efficiency.
But even more than a near-term increase in evals, our eyes have been opened to what’s possible. Composable agents are coming, whether we build it or someone else does. And it’s going to be open source (whether we build it or someone else does).
Thanks for reading, now go check out our newly open source repo! We put some effort into the README!
(🎶 Also, check out the song version of this article, entitled “Delete your spaghetti code”)
We’ll be launching every day this week on social media and Discord. At the end of the week, we’ll post one more Substack article to wrap things up.
Cheers and happy coding!
—James
Big thanks to Danny for the video-editing and graphics, and Akio for thoughtful feedback reviewing a draft.
